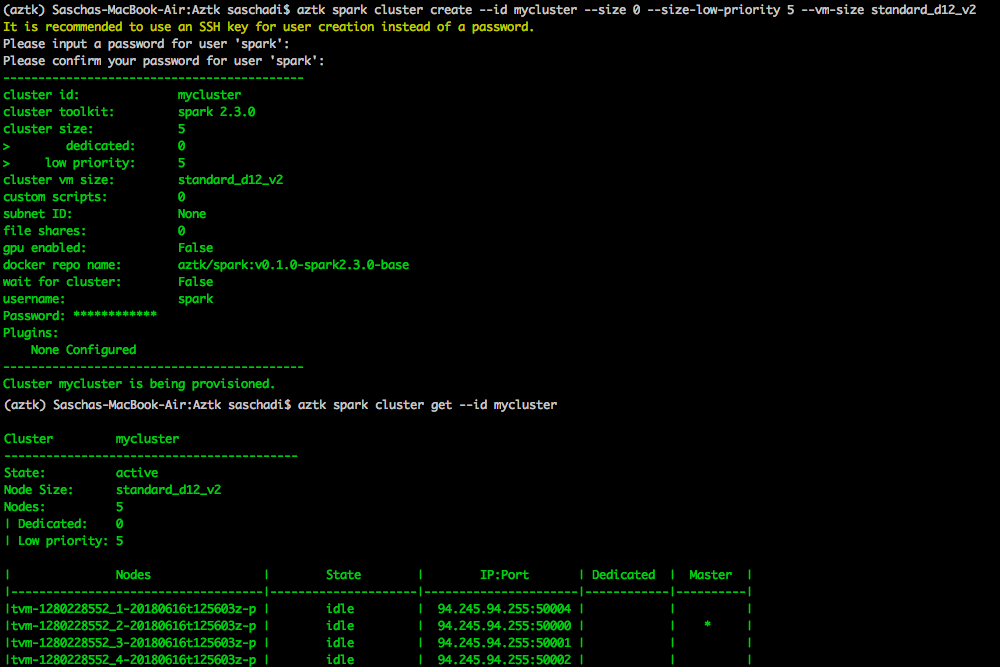
In my last post, I showed you how to provision a low-cost Apache Spark cluster on Microsoft Azure, with the help of the Azure Batch service, Low Priority Virtual Machines, and the Azure Distributed Data Engineering Toolkit (AZTK).
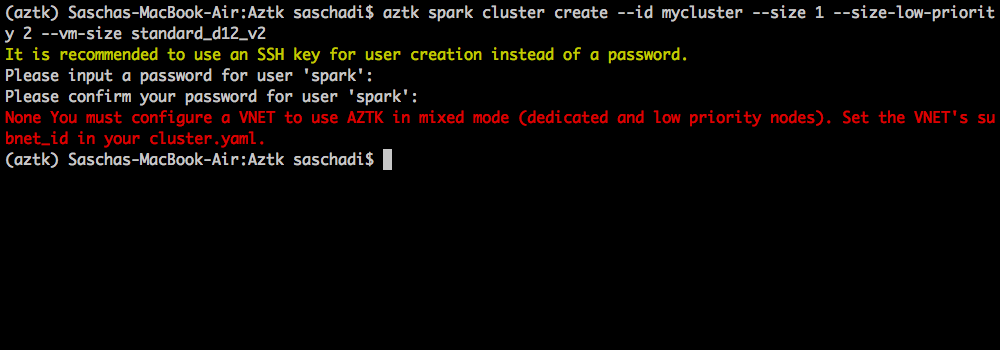
But have you tried to mix a cluster with Dedicated-, as well as Low Priority-Virtual Machines?
If you did, you propably run into an error…